Zadałeś trudne pytanie, ale jestem trochę zaskoczony, że różne wskazówki, które zostały ci zasugerowane, otrzymały tak mało uwagi. Głosowałem za nimi wszystkimi, ponieważ uważam, że są one w zasadzie pożytecznymi odpowiedziami, chociaż w swojej rzeczywistej formie wzywają do dalszej pracy bibliograficznej.
Zastrzeżenie: Nigdy nie miałem do czynienia z taką problem, ale regularnie muszę ujawniać wyniki statystyczne, które mogą różnić się od a priori przekonań lekarzy i wiele się uczę, odkrywając ich tok rozumowania. Mam również pewne doświadczenie w nauczaniu ludzkiej decyzji / wiedzy z perspektywy sztucznej inteligencji i nauk kognitywnych i myślę, że to, o co pytałeś, nie jest tak dalekie od tego, w jaki sposób eksperci faktycznie decydują, że dwa obiekty są podobne lub nie, na podstawie ich atrybutów i wspólne rozumienie ich relacji.
Z twojego pytania zwróciłem uwagę na dwa interesujące stwierdzenia. Pierwsza dotyczyła tego, jak ekspert ocenia podobieństwo lub różnicę między dwoma zestawami pomiarów:
Nie obchodzi mnie, czy istnieje jakaś zależność między atrybutem X i Y. Na czym mi zależy jeśli lekarz uważa, że istnieje związek między X i Y.
Drugi,
Jak mogę przewidzieć, jakie według niego jest podobieństwo? Czy patrzą na określone atrybuty?
wygląda na to, że jest on w pewnym stopniu podciągnięty do pierwszego, ale wydaje się być ściślej powiązany z najważniejszymi atrybutami, które pozwalają na wyraźne oddzielenie obiekty zainteresowania.
Na pierwsze pytanie odpowiedziałbym: Cóż, jeśli nie ma charakterystycznej lub obiektywnej relacji między dowolnymi dwoma przedmiotami, jakie byłoby uzasadnienie dla stworzenia hipotetycznego? Raczej myślę, że pytanie powinno brzmieć: jeśli mam tylko ograniczone zasoby (wiedza, czas, dane), aby podjąć decyzję, w jaki sposób mogę zoptymalizować swój wybór? Na drugie pytanie moja odpowiedź brzmi: Chociaż wydaje się, że częściowo zaprzecza to twojemu wcześniejszemu twierdzeniu (jeśli w ogóle nie ma związku, oznacza to, że dostępne atrybuty nie są dyskryminujące ani bezużyteczne), myślę, że przez większość czasu jest to kombinacja atrybutów, która ma sens, a nie tylko to, jak dana osoba osiąga wyniki w pojedynczym atrybucie.
Pozwólcie, że rozwodzę się nad tymi dwoma punktami. Istoty ludzkie mają ograniczoną lub ograniczoną racjonalność i może podjąć decyzję (często właściwą) bez sprawdzania wszystkich możliwych rozwiązań. Istnieje również ścisły związek z abdukcyjnym rozumowaniem.
Powszechnie wiadomo, że istnieje pewna rozbieżność między poszczególnymi ocenami, a nawet między orzeczeniami tego samego biegłego wydanymi w dwóch przypadkach. Tym właśnie interesują nas badania niezawodności. Ale chcesz wiedzieć, w jaki sposób ci eksperci opracowują swoje oceny. W psychologii poznawczej istnieje ogromna liczba artykułów na ten temat, zwłaszcza na temat tego, że sądy względne są łatwiejsze i bardziej wiarygodne niż absolutne . Pod tym względem decyzje lekarzy są interesujące, ponieważ potrafią podjąć „dobrą” decyzję mając ograniczoną ilość informacji, ale jednocześnie korzystają z coraz większej wewnętrznej bazy wiedzy, z której mogą wyciągać oczekiwane relacje (ekstrapolacja) . Innymi słowy, mają wbudowaną maszynerię wnioskowania (zakładaną, że jest to hipotetyczno-dedukcyjna) maszyneria i gromadzą pozytywne dowody lub kontrfakty wynikające z doświadczenia lub praktyki. Odtwarzanie tej zdolności wnioskowania i użycie wiedzy deklaratywnej było celem kilku systemów eksperckich lub reguł produkcyjnych w latach 70., z których najsłynniejszym był MYCIN, a bardziej ogólnie Artifical Inteligencja na początku 1946 r. (Czy w sztucznym systemie możemy odtworzyć inteligentne zachowanie obserwowane u człowieka?). Automatyczne traktowanie mowy, rozwiązywanie problemów, wizualne rozpoznawanie kształtów są nadal aktywnymi projektami w dzisiejszych czasach i wszystkie mają do czynienia z identyfikacją najistotniejszych cech i ich relacji, aby podjąć odpowiednią decyzję (tj. dwa różne procesy generujące?).
Podsumowując, nasi lekarze są w stanie wyciągnąć optymalne wnioski z ograniczonej ilości danych, kompensując hałas, który powstaje po prostu jako produkt uboczny indywidualnej zmienności (na poziomie pacjentów). Tak więc istnieje wyraźny związek ze statystyką i teorią prawdopodobieństwa, a pytanie brzmi, co świadoma lub podświadoma metodologia pomaga lekarzom w formułowaniu ich sądów. Sieci semantyczne (SN), sieci przekonań i drzewa decyzyjne są odpowiednie dla zadanego pytania. Cytowany artykuł dotyczy wykorzystania ontologii jako podstawy formalnych sądów, ale jest to nic innego jak rozszerzenie SN i wiele projektów zostało zainicjowanych w tym kierunku (mogę pomyśleć o Ontologia genów do badań genomicznych, ale wiele innych istnieje w różnych dziedzinach).
Spójrzmy teraz na następującą hierarchiczną klasyfikację kategorii diagnostycznych (jest z grubsza zaczerpnięta z Dunn 1989, str. 25):
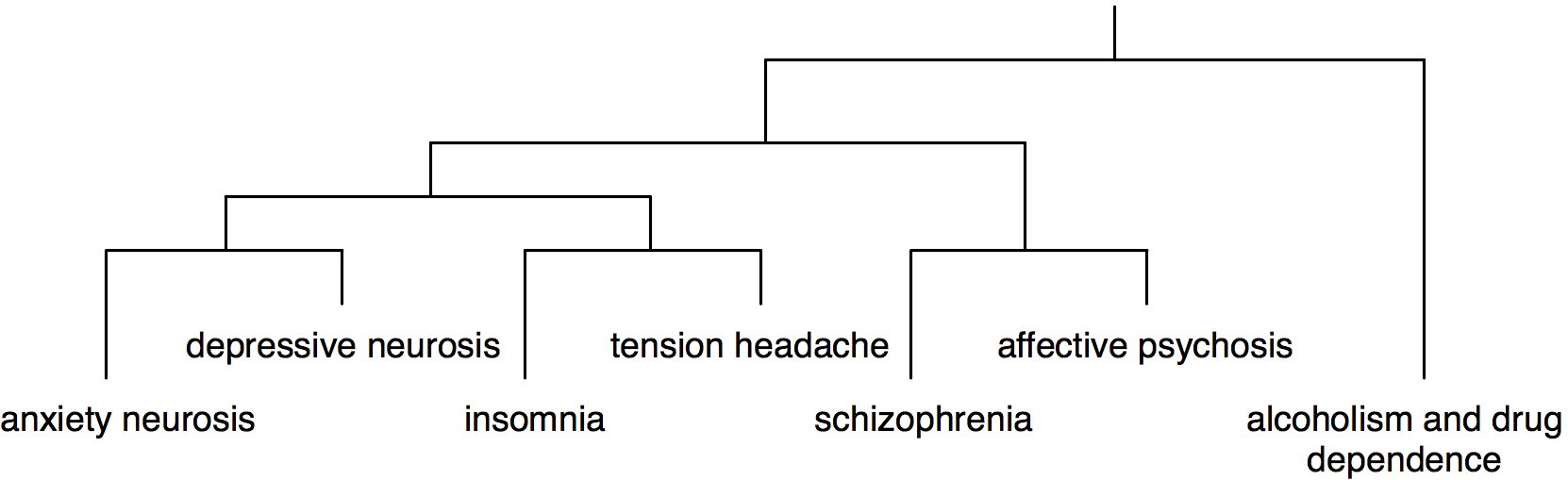
A teraz spójrz na klasyfikację ICD; Myślę, że nie jest to zbyt daleko od tej schematycznej klasyfikacji. Zaburzenia psychiczne są podzielone na różne kategorie, z których niektóre są sobie bliższe. To, co czyni je podobnymi, to bliskość ich ekspresji (fenotypu) u każdego pacjenta oraz fakt, że mają pewne podobieństwa w etiologii somatycznej / psychologicznej. Ocena, czy dwóch lekarzy dokonałoby tej samej diagnozy, jest typowym przykładem badania porozumienia między oceniającymi , w którym dwóch psychiatrów jest proszonych o umieszczenie każdego z kilku pacjentów w wykluczających się kategoriach. Hierarchiczna struktura powinna znaleźć odzwierciedlenie w sporze między poszczególnymi lekarzami, to znaczy mogą nie zgadzać się co do dokładniejszego rozróżnienia między klasami diagnostycznymi (listkami), ale gdyby nie zgadzali się między bezsennością a schizofrenią, cóż, byłoby to trochę niepokojące. . To, w jaki sposób ci dwaj lekarze decydują, do której klasy należy dany pacjent, jest tylko problemem skupiającym: Jakie jest prawdopodobieństwo, że dwie osoby, biorąc pod uwagę zestaw obserwowanych wartości różnych atrybutów, będą na tyle podobne, że zdecyduję, że mają to samo członkostwo w klasie?
Otóż, niektóre atrybuty mają większy wpływ niż inne i właśnie to znajduje odzwierciedlenie w wadze przypisanej danemu atrybutowi w analizie klas ukrytych (którą można traktować jako rozszerzenie probabilistyczne metod grupowania, takich jak k-średnie) lub zmienna ważność w Random Forests. Musimy pakować rzeczy do pudełek, bo na pierwszy rzut oka jest to prostsze. Problem polega na tym, że często rzeczy do pewnego stopnia się pokrywają, więc musimy wziąć pod uwagę różne poziomy kategoryzacji.
W rzeczywistości analiza skupień jest sercem rzeczywistych kategorii DSM, a wiele artykułów faktycznie obraca się wokół przypisania jednego pacjenta do określonej kategorii syndromowej, w oparciu o profil jego odpowiedzi na baterię ocen neuropsychologicznych . Wygląda to po prostu na podejście podtypów ; Za każdym razem staramy się zawęzić wstępnie ustaloną kategorię diagnostyczną, dodając reguły wyjątków lub dodatkowy istotny objaw lub upośledzenie.
Podobnym tematem są drzewa decyzyjne , które są zdecydowanie najlepiej rozumianymi przez lekarzy technikami statystycznymi. Przez większość czasu opisywali zagnieżdżoną serię twierdzeń logicznych (Czy boli cię gardło? Jeśli tak, czy masz temperaturę? Itd.), Ale spójrz na przykład publicznego drzewa diagnostycznego grypy ), zgodnie z którym możemy podjąć decyzję dotyczącą bliskości pacjentów (tj. jak podobni pacjenci są uwzględniani w atrybutach branych pod uwagę przy budowaniu drzewa - im bliżej są, tym większe jest prawdopodobieństwo, że znajdą się w tym samym liściu). Reguły asocjacji i algorytm C4.5 opierają się na tym samym pomyśle. W pokrewnym temacie jest metoda indukcji reguł pacjenta (PRIM). Teraz musimy wyraźnie rozróżnić wszystkie te metody, które efektywnie wykorzystują dużą ilość danych i obejmują gromadzenie lub przyspieszanie w celu zrekompensowania kruchości modelu lub problemów z nadmiernym dopasowaniem, a lekarzami, którzy nie mogą przetwarzać ogromnych ilości danych w automatycznym i algorytmiczny sposób. Ale w przypadku małej lub średniej liczby deskryptorów myślę, że mimo wszystko działają one całkiem dobrze.
Jednak podejście tak lub nie nie jest panaceum. W genetyce behawioralnej i psychiatrii powszechnie twierdzi się, że podejście klasyfikacyjne nie jest prawdopodobnie najlepszą drogą i że powszechne choroby (zaburzenia uczenia się, depresja, zaburzenia osobowości itp.) Odzwierciedlają raczej kontinuum niż klasy o przeciwnej wartościowości. Nikt nie jest doskonały!
Podsumowując, myślę, że lekarze faktycznie posiadają rodzaj zinternalizowanego mechanizmu wnioskowania, który pozwala im przypisywać pacjentów do odrębnych klas, które charakteryzują się ważoną kombinacją dostępnych dowodów; innymi słowy, są w stanie efektywnie organizować swoją wiedzę, a te wewnętrzne reprezentacje i relacje, które dzielą, mogą zostać wzmocnione w trakcie doświadczenia. Rozumowanie oparte na przypadkach prawdopodobnie również w pewnym momencie wchodzi w grę. Wszystko to może podlegać (a) korekcie z nowo dostępnymi danymi (nie działamy po prostu jako ostateczne klasyfikatory binarne i jesteśmy w stanie włączyć nowe dane do naszego procesu decyzyjnego) oraz (b) subiektywne uprzedzenia wynikające z wcześniejszych doświadczeń błędne reguły asocjacji stworzone przez siebie. Są jednak podatne na błędy, ponieważ każdy system decyzyjny ...
Wszystkie techniki statystyczne odzwierciedlające te kroki - drzewa decyzyjne, gromadzenie / zwiększanie, analiza skupień, analiza utajonych skupień - wydają się odpowiednie dla twoich pytań , chociaż ich wystąpienie może być trudne w jednej regule decyzyjnej.
Oto kilka odniesień, które mogą być pomocne jako pierwszy początek w podejmowaniu decyzji przez lekarzy:
- System wspomagania decyzji klinicznych dla lekarzy określenie odpowiedniego badania radiologicznego
- Grzymala-Busse, JW. Wybrane algorytmy uczenia maszynowego na podstawie przykładów. Fundamenta Informaticae 18 (1993), 193–207
- Santiago Medina, L, Kuntz, KM i Pomeroy, S. Dzieci z bólem głowy podejrzane o guza mózgu : Analiza opłacalności strategii diagnostycznych. Pediatrics 108 (2001), 255-263
- Building Better Algorithms for the Diagnosis of Nonraumatic Headache
- Jenkins, J, Shields, M, Patterson, C i Kee, F. Podejmowanie decyzji w zaostrzeniach astmy: analiza oceny klinicznej. Arch Dis Child 92 (2007), 672–677
- Croskerry, P. Osiąganie jakości w podejmowaniu decyzji klinicznych: strategie poznawcze i wykrywanie uprzedzeń. Acad Emerg Med 9 (11) (2002), 1184–204.
- Cahan, A, Gilon, D, Manor, O i Paltiel. Rozumowanie probabilistyczne i podejmowanie decyzji klinicznych: czy lekarze przeceniają prawdopodobieństwa diagnostyczne? QJM 96 (10) (2003), 763-769
- Wegwarth, O, Gaissmaier, W i Gigerenzer , G. Inteligentne strategie dla lekarzy i lekarzy stażystów: heurystyka w medycynie. Edukacja medyczna 43 (2009), 721–728