Przez chwilę byłem również zaskoczony kluczami, zapytaniami i wartościami w mechanizmach uwagi. Po przeszukaniu sieci i przeanalizowaniu odpowiednich informacji mam jasny obraz tego, jak działają klucze, zapytania i wartości oraz dlaczego mają działać!
Zobaczmy, jak działają i dlaczego działają
W modelu seq2seq kodujemy sekwencję wejściową do wektora kontekstu, a następnie przekazujemy ten wektor kontekstu do dekodera, aby uzyskać oczekiwany dobry wynik.
Jeśli jednak sekwencja wejściowa jest długa, opieranie się tylko na jednym wektorze kontekstu staje się mniej efektywne. Potrzebujemy wszystkich informacji ze stanów ukrytych w sekwencji wejściowej (koder) dla lepszego dekodowania (mechanizm uwagi).
Poniżej pokazano jeden ze sposobów wykorzystania wejściowych stanów ukrytych:
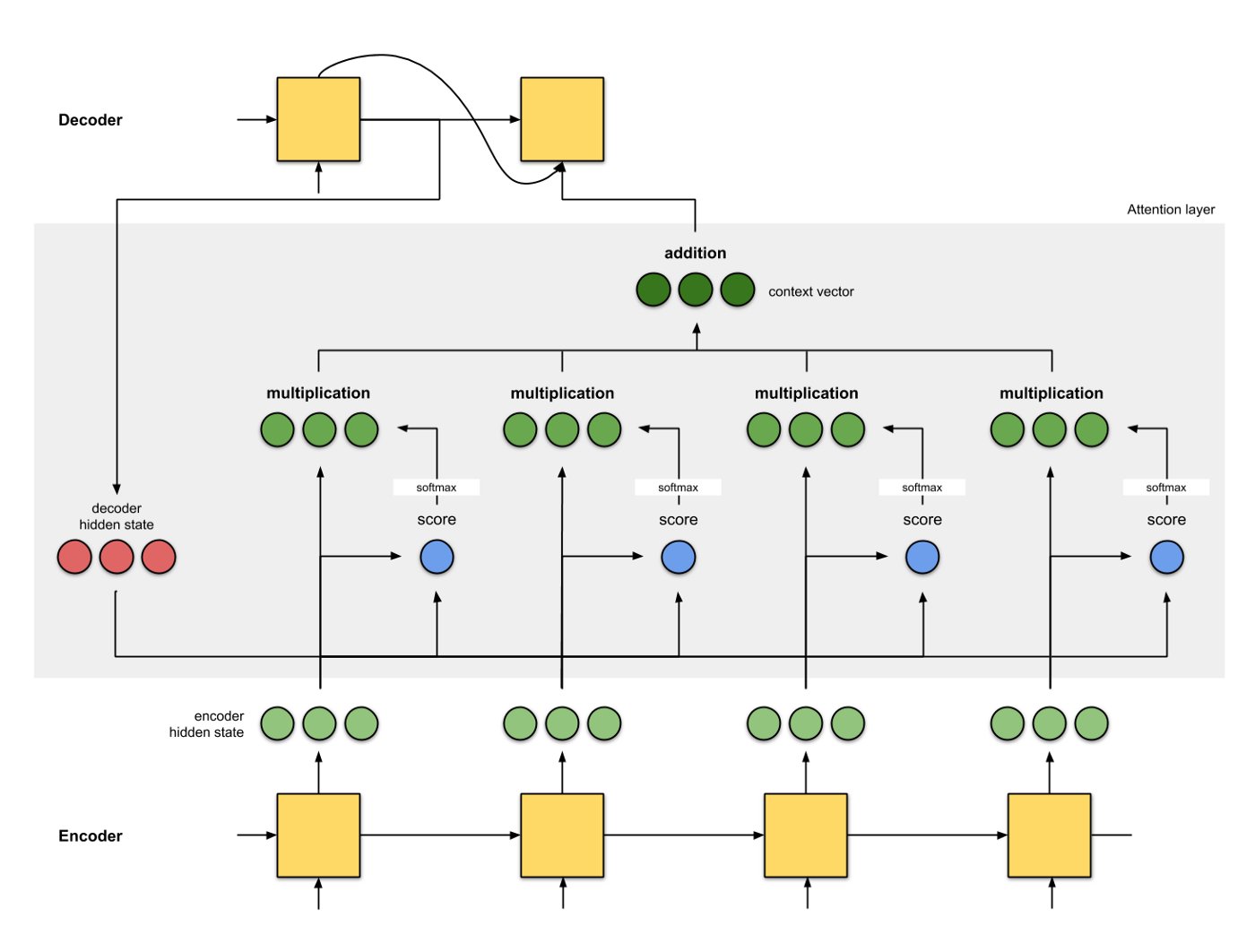 Źródło obrazu: https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
Źródło obrazu: https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
Innymi słowy, w tym mechanizmie uwagi wektor kontekstu jest obliczany jako ważona suma wartości, gdzie waga przypisana do każdej wartości jest obliczana przez funkcję zgodności zapytania z odpowiednim kluczem (jest to nieco zmodyfikowane zdanie z [Attention Is All You Need] https://arxiv.org/pdf/1706.03762.pdf).
Tutaj zapytanie pochodzi ze stanu ukrytego dekodera, klucz i wartość pochodzą ze stanów ukrytych kodera (klucz i wartość są takie same na tym rysunku). Wynik to zgodność między zapytaniem a kluczem, która może być iloczynem skalarnym między zapytaniem a kluczem (lub inną formą zgodności). Wyniki przechodzą następnie przez funkcję softmax, aby uzyskać zestaw wag, których suma jest równa 1. Każda waga mnoży odpowiadające jej wartości, aby uzyskać wektor kontekstu, który wykorzystuje wszystkie wejściowe stany ukryte.
Zauważ, że jeśli ręcznie ustawimy wagę ostatniego wejścia na 1 i wszystkie jego pierwszeństwa na 0, zredukujemy mechanizm uwagi do oryginalnego mechanizmu wektora kontekstu seq2seq. Oznacza to, że nie zwraca się uwagi na wcześniejsze stany kodera wejściowego.
Rozważmy teraz mechanizm samokontroli, jak pokazano na poniższym rysunku:
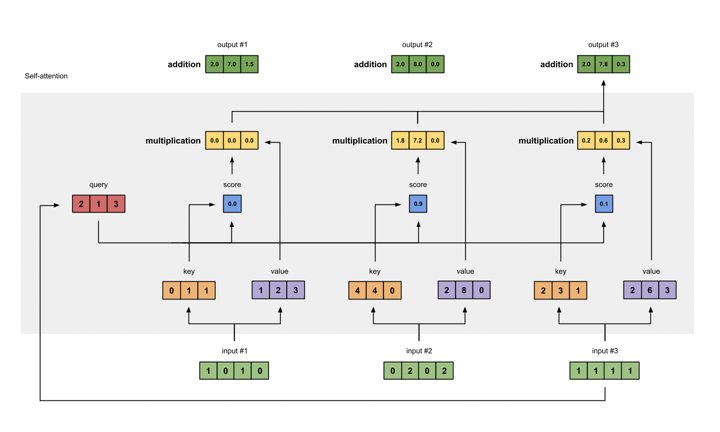 Źródło obrazu: https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a
Źródło obrazu: https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a
Różnica w stosunku do powyższego rysunku polega na tym, że zapytania, klucze i wartości są transformacjami odpowiednich wektorów stanu wejściowego. Pozostałe pozostają takie same.
Zauważ, że nadal możemy używać oryginalnych wektorów stanu kodera jako zapytań, kluczy i wartości. Dlaczego więc potrzebujemy transformacji? Przekształcenie to po prostu mnożenie macierzy, takie jak to:
Zapytanie = I x W (Q)
Klucz = I x W (K)
Wartość = I x W (V)
gdzie I jest wektorem stanu wejściowego (kodera), a W (Q), W (K) i W (V) są odpowiednimi macierzami do przekształcenia wektora I w wektory Query, Key, Value.
Jakie są zalety tego mnożenia macierzy (transformacji wektorowej)?
Przypomnij sobie efekt rozkładu na wartości osobliwe (SVD), jak na poniższym rysunku:

Źródło obrazu: https://youtu.be/K38wVcdNuFc?t=10
Mnożąc wektor wejściowy przez macierz V (z SVD), uzyskujemy lepszą reprezentację do obliczenia zgodności między dwoma wektorami, jeśli te dwa wektory są podobne w przestrzeni tematów, jak pokazano na przykładzie na rysunku.
A tych macierzy do transformacji można się nauczyć w sieci neuronowej!
Krótko mówiąc, mnożąc wektor wejściowy przez macierz, otrzymaliśmy:
1) lepsza (utajona) reprezentacja wektora wejściowego;
2) konwersja wektora wejściowego na przestrzeń o pożądanym wymiarze, powiedzmy, z wymiaru 5 do 2, lub z n na m itd. (co jest praktycznie przydatne);
gdzie macierzy można się nauczyć (bez ręcznego ustawiania).
Mam nadzieję, że pomoże ci to zrozumieć zapytania, klucze i wartości w mechanizmie (samo) uwagi głębokich sieci neuronowych.