Zwykle nie nazywałbyś wartości obserwowanej „wartością szacunkową”.
Jednak pomimo tego obserwowana wartość jest technicznie oszacowaniem średniej w jej poszczególnych $ x $, a potraktowanie jej jako oszacowania faktycznie powie nam sens, w którym OLS jest lepszy w szacowaniu średniej.
Ogólnie rzecz biorąc, regresja jest używana w sytuacji, gdy gdybyś pobrał inną próbkę z tymi samymi $ x $, nie uzyskałbyś takich samych wartości $ y $. W zwykłej regresji traktujemy $ x_i $ jako stałe / znane ilości, a odpowiedzi, $ Y_i $ jako zmienne losowe (z obserwowanymi wartościami oznaczonymi $ y_i $).
Używając bardziej powszechnego zapisu, piszemy
$$ Y_i = \ alpha + \ beta x_i + \ varepsilon_i $$
Pojęcie szumu $ \ varepsilon_i $ jest ważne, ponieważ obserwacje nie są prawidłowe na linii populacji (gdyby tak było, regresja nie byłaby potrzebna; dowolne dwa punkty dałyby linię populacji); model dla $ Y $ musi uwzględniać wartości, które przyjmuje, aw tym przypadku rozkład losowych błędów uwzględnia odchylenia od („prawdziwej”) linii.
Oszacowanie średniej w punkcie $ x_i $ dla zwykłej regresji liniowej ma wariancję
$$ \ Big (\ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} \ Big) \, \ sigma ^ 2 $$
natomiast oszacowanie oparte na wartości obserwowanej ma wariancję $ \ sigma ^ 2 $.
Można pokazać, że dla $ n $ co najmniej 3, $ \, \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum (x_i- \ bar {x}) ^ 2} $ wynosi nie więcej niż 1 (ale może być - aw praktyce zwykle jest - znacznie mniejsze). [Dalej, kiedy oszacujesz dopasowanie na $ x_i $ na $ y_i $, pozostaje Ci również kwestia, jak oszacować $ \ sigma $.]
Zamiast jednak kontynuować formalną demonstrację, zastanów się przykład, który, mam nadzieję, może być bardziej motywujący.
Niech $ v_f = \ frac {1} {n} + \ frac {(x_i- \ bar {x}) ^ 2} {\ sum ( x_i- \ bar {x}) ^ 2} $, współczynnik, przez który mnoży się wariancję obserwacji, aby otrzymać wariancję dopasowania na poziomie $ x_i $.
Jednak popracujmy nad skalą względnego błędu standardowego zamiast względnej wariancji (to znaczy, spójrzmy na pierwiastek kwadratowy z tej wielkości); przedziały ufności dla średniej w określonym $ x_i $ będą wielokrotnością $ \ sqrt {v_f} $.
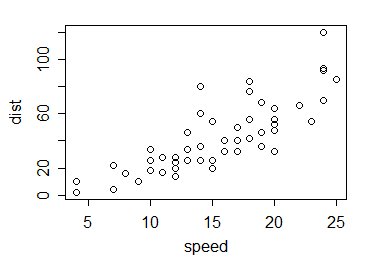
A więc do przykładu. Weźmy dane cars w R; to jest 50 obserwacji zebranych w latach dwudziestych XX wieku na temat prędkości samochodów i odległości potrzebnych do zatrzymania:
Jak więc obliczają się wartości $ \ sqrt {v_f} $ porównać z 1? W ten sposób:
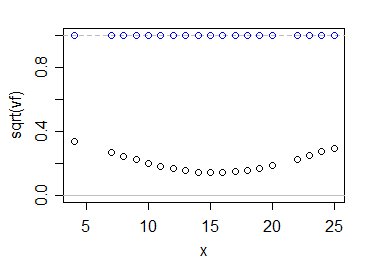
Niebieskie kółka pokazują wielokrotności $ \ sigma $ dla twojego oszacowania, podczas gdy czarne pokazują to dla zwykłego oszacowania najmniejszych kwadratów. Jak widać, wykorzystanie informacji ze wszystkich danych znacznie zmniejsza naszą niepewność co do tego, gdzie leży średnia populacji - przynajmniej w tym przypadku i oczywiście biorąc pod uwagę, że model liniowy jest poprawny.
W rezultacie , jeśli wykreślimy (powiedzmy) 95% przedział ufności dla średniej dla każdej wartości x $ (w tym w miejscach innych niż obserwacja), granice przedziału przy różnych $ x $ są zwykle małe w porównaniu z zmienność danych:
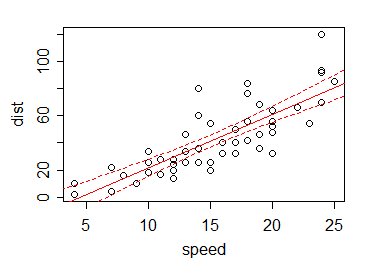
Jest to korzyść z „zapożyczenia” informacji z wartości danych innych niż bieżąca.
Rzeczywiście, możemy wykorzystać informacje z innych wartości - poprzez zależność liniową - aby uzyskać dobre oszacowania wartości w miejscach, w których nawet nie mamy danych. Weź pod uwagę, że w naszym przykładzie nie ma danych przy x = 5, 6 lub 21. Przy sugerowanym estymatorze nie mamy tam żadnych informacji - ale za pomocą linii regresji możemy nie tylko oszacować średnią w tych punktach (i przy 5,5 i 12,8 i tak dalej), możemy podać dla niej przedział - choć znowu taki, który opiera się na stosowności założeń liniowości (i stałej wariancji Y $ s i niezależności).