To niezwykłe, że nie pasuje do przechwycenia i generalnie niewskazane - należy to zrobić tylko wtedy, gdy wiesz, że jest to 0, ale myślę, że (i fakt, że nie możesz porównać $ R ^ 2 $ dla dopasowania z i bez punkt przecięcia z osią) jest już dobrze i naprawdę pokryty (jeśli być może trochę zawyżony w przypadku przecięcia z osią zerową); Chcę skupić się na Twoim głównym problemie, którym jest to, że potrzebujesz funkcji dopasowanej, aby była pozytywna, chociaż w części mojej odpowiedzi wracam do problemu z punktem zerowym.
Najlepszy sposób, aby uzyskać zawsze dopasowanie pozytywne to dopasowanie czegoś, co zawsze będzie pozytywne; po części zależy to od funkcji, które należy dopasować.
Jeśli model liniowy był w dużej mierze wygodnym modelem (a nie pochodził ze znanej zależności funkcjonalnej, która mogłaby wynikać np. z modelu fizycznego), zamiast tego może pracować z czasem logowania; wtedy dopasowany model ma wartość dodatnią w $ t $. Alternatywnie możesz pracować z szybkością, a nie z czasem - ale wtedy przy dopasowaniach liniowych może pojawić się problem z małymi prędkościami (długimi czasami).
Jeśli wiesz, że Twoja odpowiedź jest liniowa w predyktorach, możesz spróbować dopasować regresję ograniczoną, ale w przypadku regresji wielokrotnej dokładna forma, której potrzebujesz, będzie zależeć od konkretnych x (nie ma jednego liniowego ograniczenia, które zadziała dla wszystkich $ x $), więc jest to bit ad-hoc.
Możesz również spojrzeć na GLM, które można wykorzystać do dopasowania modeli, które mają nieujemne dopasowane wartości i mogą (jeśli jest to wymagane) nawet mieć $ E (Y) = X \ beta $ .
Na przykład, można dopasować gamma GLM z łączem tożsamości. Nie powinieneś skończyć z ujemną dopasowaną wartością dla któregokolwiek z twoich x (ale w niektórych przypadkach możesz mieć problemy ze zbieżnością, jeśli wymusisz łącze tożsamości tam, gdzie naprawdę nie będzie pasować).
Oto przykład przykład: zbiór danych cars w R, który rejestruje prędkość i drogę hamowania (odpowiedź).
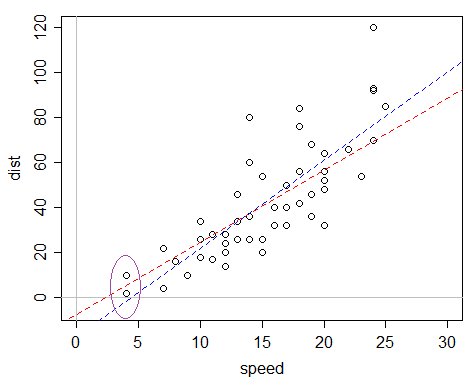
Można by powiedzieć "och, ale odległość dla prędkości 0 jest gwarantowana, więc powinniśmy pominąć punkt przecięcia", ale problem z tym rozumowaniem polega na tym, że model jest błędnie określony na kilka sposobów, a argument ten działa tylko dobrze wystarczy, gdy model nie jest błędnie określony - model liniowy z punktem przecięcia zerowym nie pasuje w tym przypadku w ogóle, podczas gdy model z punktem przecięcia jest w rzeczywistości w połowie przyzwoitym przybliżeniem, mimo że nie jest w rzeczywistości „poprawny”.
Problem polega na tym, że jeśli dopasujesz zwykłą regresję liniową, dopasowany punkt przecięcia z osią jest w dużym stopniu ujemny, co powoduje, że dopasowane wartości są ujemne.
Niebieska linia to dopasowanie OLS; dopasowane wartości dla najmniejszych wartości x w zestawie danych są ujemne. Czerwona linia to gamma GLM z łączem identyfikacyjnym - mając ujemny punkt przecięcia, ma tylko dodatnie dopasowane wartości. Ten model ma wariancję proporcjonalną do średniej, więc jeśli okaże się, że dane są bardziej rozłożone w miarę wydłużania się oczekiwanego czasu, może być szczególnie odpowiedni.
Jest to więc jedno z możliwych alternatywnych rozwiązań, które warto wypróbować. To prawie tak proste, jak dopasowanie regresji w R.
Jeśli nie potrzebujesz łącza tożsamości, możesz rozważyć inne funkcje łączenia, takie jak łącze dziennika i łącze odwrotne, które odnoszą się do transformacji już omówione, ale bez potrzeby rzeczywistej transformacji.
Ponieważ ludzie zwykle o to proszą, oto kod mojej działki:
plot (dist ~ speed, data = cars, xlim = c (0, 30), ylim = c (-5,120)) abline (h = 0, v = 0, col = 8) abline (glm (dist ~ speed, data = cars, family = Gamma (link = identity)), col = 2 , lty = 2) abline (lm (dist ~ speed, data = cars), col = 4, lty = 2)
(Elipsa została później dodana ręcznie, chociaż jest to dość łatwe do zrobienia również w R)