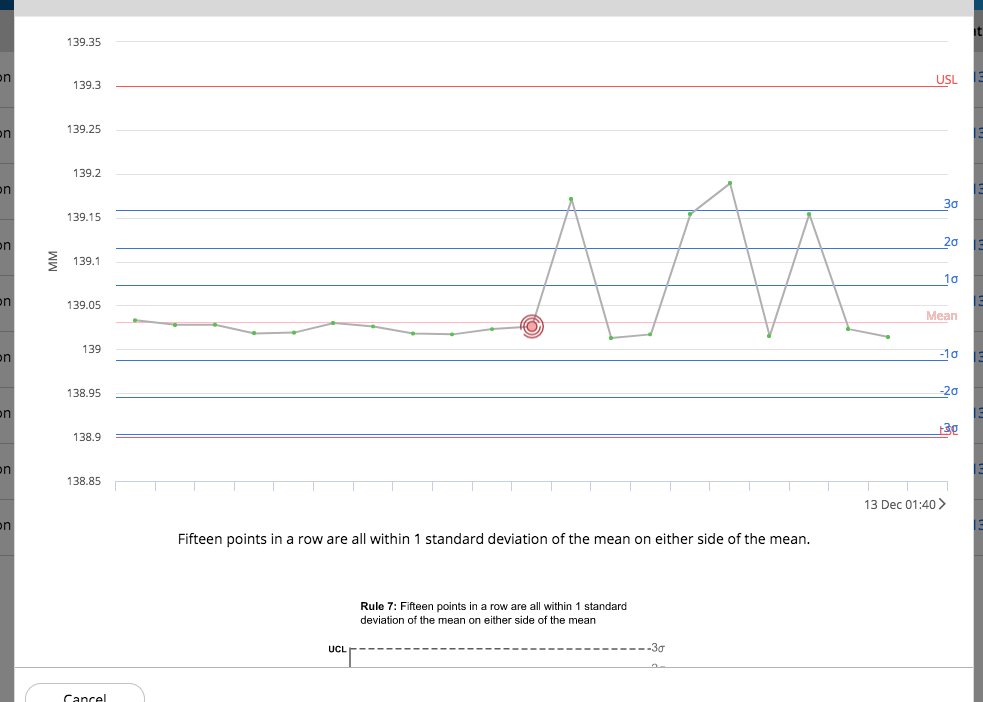
zastrzeżenie - ta metoda jest ad hoc i nie wymaga rygorystycznych badań. Używasz na własne ryzyko :)
To, co okazało się całkiem dobre, to zmniejszenie trafności wkładu punktów do średniej przez square jego liczby odchyleń standardowych od średniej, ale tylko wtedy, gdy punkt jest więcej niż jednym odchyleniem standardowym od średniej.
Kroki:
- Jak zwykle obliczyć średnią i odchylenie standardowe.
- Oblicz ponownie średnią, ale tym razem dla każdej wartości, jeśli jest to . Więcej niż jedno odchylenie standardowe od średniej zmniejsza jej udział w średniej. Aby zmniejszyć jego udział, należy podzielić jego wartość przez kwadrat liczby odchyleń przed dodaniem do całości. Ponieważ wnosi mniejszy wkład, musimy zmniejszyć N, więc odejmij 1-1 / (kwadrat odchylenia wartości) od N.
- Oblicz ponownie odchylenie standardowe, ale użyj tej nowej średniej zamiast starej.
przykład:
stddev = 0,5
średnia = 10
wartość = 11
więc odchylenia = odległość od średniej / odchylenie standardowe = | 10-11 | /0,5 = 2
więc wartość zmienia się z 11 na 11 / (2) ^ 2 = 11/4
także N się zmienia, zostaje zredukowane do N-3/4.
kod:
def mean (data):
"" "Zwraca przykładową średnią arytmetyczną danych." ""
n = len (dane)
if n < 1:
podnieść ValueError ('średnia wymaga co najmniej jednego punktu danych')
return 1.0 * sum (data) / n # w Pythonie 2 użyj sum (data) / float (n)
def _ss (dane):
"" "Zwracana suma odchyleń kwadratowych danych sekwencji." ""
c = średnia (dane)
ss = suma ((x-c) ** 2 dla x w danych)
powrót ss, c
def stddev (dane, ddof = 0):
"" "Oblicza odchylenie standardowe populacji
domyślnie; określ ddof = 1, aby obliczyć próbkę
odchylenie standardowe."""
n = len (dane)
if n < 2:
podnieść ValueError ('wariancja wymaga co najmniej dwóch punktów danych')
ss, c = _ss (dane)
pvar = ss / (n-ddof)
powrót pvar ** 0,5, c
def rob_adjusted_mean (wartości, s, m):
n = 0,0
tot = 0,0
dla v w wartościach:
diff = abs (v - m)
odchylenia = różn./s
jeśli odchylenia > 1:
# jest wartością odstającą, więc zmniejsz jej trafność / wagę o kwadrat liczby odchyleń
n + = 1,0 / odchylenie ** 2
tot + = v / odchylenia ** 2
jeszcze:
n + = 1
tot + = v
powrót tot / n
def rob_adjusted_ss (wartości, s, m):
"" "Zwracana suma odchyleń kwadratowych danych sekwencji." ""
c = rob_adjusted_mean (wartości, s, m)
ss = suma ((x-c) ** 2 dla x w wartościach)
powrót ss, c
def rob_adjusted_stddev (dane, s, m, ddof = 0):
"" "Oblicza odchylenie standardowe populacji
domyślnie; określ ddof = 1, aby obliczyć próbkę
odchylenie standardowe."""
n = len (dane)
if n < 2:
podnieść ValueError ('wariancja wymaga co najmniej dwóch punktów danych')
ss, c = rob_adjusted_ss (dane, s, m)
pvar = ss / (n-ddof)
powrót pvar ** 0,5, c
s, m = stddev (wartości, ddof = 1)
drukuj s, m
s, m = rob_adjusted_stddev (wartości, s, m, ddof = 1)
drukuj s, m
dane wyjściowe przed i po regulacji moich 50 pomiarów:
0.0409789841609 139.04222
0,0425867309757 139,030745443